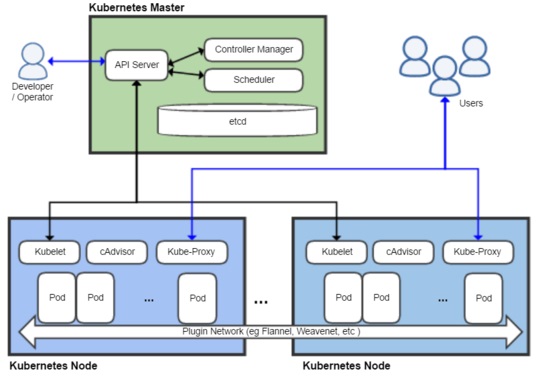
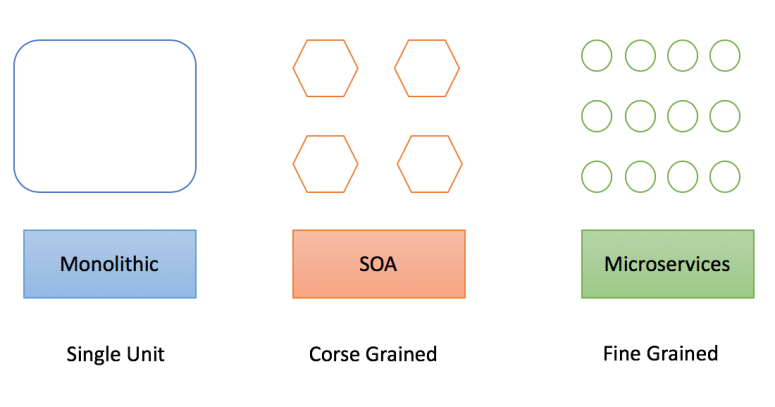
A few months ago, I had the opportunity to provide guidance to a small agile development team getting started with Red Hat OpenShift Online.
The team needed to quickly stand up a couple environments (development, test, staging, prod), set up a CI/CD pipeline (Git, Jenkins, SonarQube, Docker, postman, and Kubernetes) to work on a 6 week MVP (minimal viable product) to build a microservices-based application using container orchestration technology.
In a nutshell, it all boiled down to three keywords: IoT, Microservices, and Kubernetes.
In our previous posts, we explored Getting Started with Red Hat OpenShift where I provided an overview of OpenShift, Kubernetes and showed an example of an application using a microservice architecture.
In this post, we’re going to dive deeper and focus on how a development team quickly setup and use continuous integration / continuous delivery (CI/CD) pipeline to automatically build, deploy and test microservices through a set of environments (think Kubernetes namespaces) as the solution is evolved and promoted through the different phases where it is constructed, verified, and promoted from one working location to another (from development to integration and finally to production)

So let’s get started with a quick review of microservices
Containerized Microservices
A microservices architecture consists of a collection of small, autonomous services. Each service is self-contained and should implement a single business capability.
In a microservices architecture, services are small, independent, and loosely coupled. They are also
- Small enough that a single small team of developers can write and maintain
- Can be deployed independently without rebuilding and redeploying the entire application
- Communicate with each other by using well-defined APIs and their internal implementation details are hidden from other services.
Here is the example of a containerized microservice-based application composed of several microservices that we shared in our earlier blog.

In this case, the application has been divided into several independent microservices. In addition, each microservice has
- business focus or specific problem it is trying to solve (such as account profile or order, shipping, etc…)
- separate development teams working on the project.
- its own life and release cycle.
- independent. Meaning few if any runtime dependencies with other microservices
- to depend on a small ecosystem (such as Zuul, AAA, logging, etc).
While many people know the benefits of using microservices, such as shorter development time, decentralized governance, and independent releases introduce challenges with versioning, testing, and configuration control.
To overcome several of these challenges we decided to use Red Hat OpenShift online as it was:
- Easy to get started with container-based development
- Cloud-based so supported geographically distributed development teams
- An extensive set of container templates that we could leverage
Red Hat OpenShift Online
Red Hat OpenShift is an enterprise-grade container platform that can be run on-premise, in the cloud. OpenShift® Online is Red Hat’s public cloud container platform used for on-demand access to OpenShift to build, deploy and manage scalable containerized applications.

It a Self-service environment that allows you to use the languages and tools you want and comes with a set of pre-created container images and templates that allow you to build and deploy your favorite application runtimes, frameworks, databases, and more in one click.
We decided to use Red Hat OpenShift online for a couple key reasons
- Easy to get started
- Support for team-based development
- An extensive set of container templates that we could leverage
Pipeline for a Single Microservice
From a team standpoint, the pipeline must allow them to be able to quickly build, test and deploy the microservice without disrupting other teams or destabilizing the application as a whole.
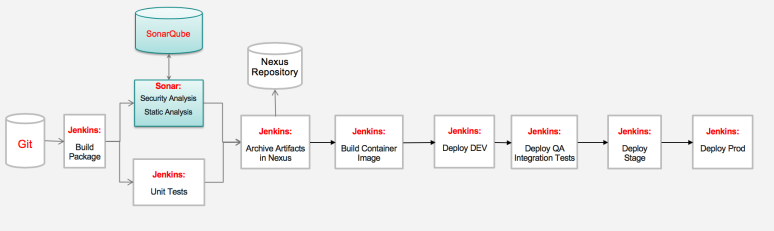
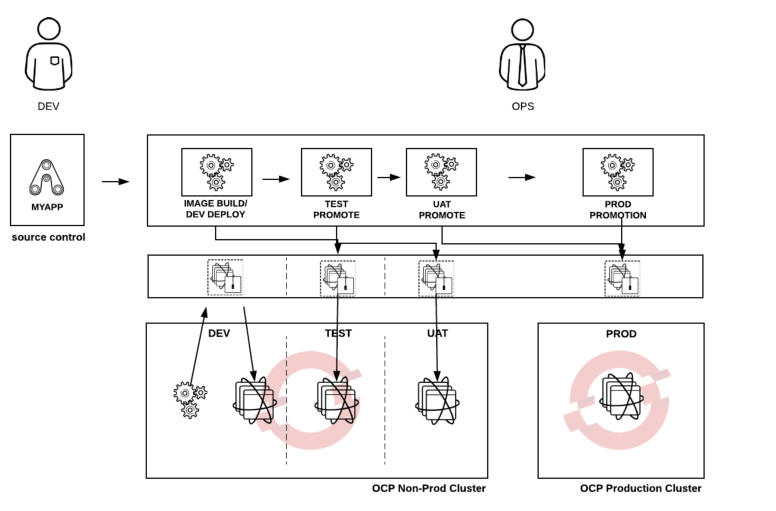
Here is a typical high-level workflow that many small development teams use to promote their work from one namespace (ie. project in OpenShift) to another
 Source: cicd-for-containerised-microservices
Source: cicd-for-containerised-microservices
The design principles used for building the pipeline are as follows::
- Each development team has its own build pipeline that they can use to build, test and deploy their services independently.
- Code changes that committed to the “develop” branch are automatically deployed to a production-like namespace (or project in OpenShift)
- Quality gates are used to enforce pipeline quality.
- A new version of the microservice can be deployed side by side with the previous version
Builds
By default, OpenShift provides support for Docker build, Source-to-Image (S2I) build, and Custom build. Using these strategies, developers can quickly produce runnable images. The diagram below illustrates the relationship between containers, images, and registries are depicted in the following diagram:

Jenkins Pipeline
In addition, OpenShift has extensive support for Jenkins and provides an out-of-the-box containerized Jenkins template that you can quickly deploy.
OpenShift’s pipeline build strategy uses pipelines for execution by the Jenkins pipeline plugin. Pipeline workflows are defined in a Jenkinsfile, either embedded directly in the build configuration or supplied in a Git repository and referenced by the build configuration.
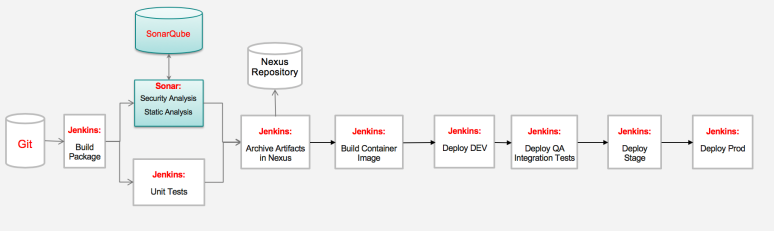
Here is a typical pipeline for a single containerized microservice with no dependencies that relies on a simple versioning strategy (version from the assembly such as pom, npm, or other).

Here are the detailed steps:
- Developer makes code changes and commits code to the local git repo
- Push code changes into the “develop” branch where a trigger has been set up to kick off an automated build.
- Unit and component tests are performed during the build procedure.
- Static code analysis is also performed to pass the source code quality gate.
- Build artifacts are published into an artifact repository, such as Nexus or Artifactory
- Build image is pushed to image repo
- Jenkins deploys the image to “Dev” namespace (called “Project” in OpenShift) where any automated test cases are kicked off. Developers are also able to perform manual/ad-hoc testing as well (teams often use tools such as postman)
- If test cases pass, image is tagged and Jenkins promotes (deploys tagged image) to the Integration project (i.e. namespace) for integration testing. Trigger integration with other microservices.
- If integration tests pass, image is tagged again and publish into a production image repository for deployment to staging or prod.
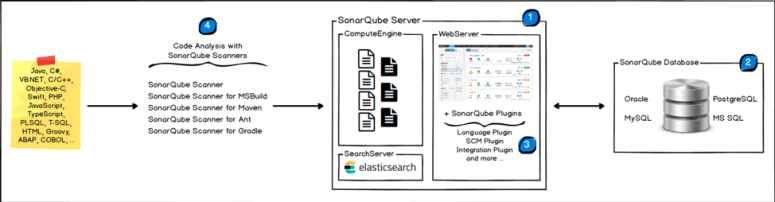
SonarQube
In an earlier post, we discussed how SonarQube scans are often included as part of the CI/CD pipelines to ensure quality by failing individual Jenkins jobs that don’t pass the Quality-Gates set by the project.
SonarQube provides built-in integrations for Maven, MSBuild, Gradle, Ant, and Makefiles. Using these tools, it is quite easy to integrate SonarQube into your CI pipeline. For example, for Maven you can use the Maven Sonar Plugin.
After CI completes, you just have a new build artifact – a Docker image file – which is pushed to the image repo. Note that many of container images available on Docker Hub won’t run on OpenShift, as it has stricter security policies. For example, OpenShift won’t run a container as root
Deployment to OpenShift Cluster
Most agile teams still must promote their application code through a series of SDLC environments (think Kubernetes namespaces) to build and test code, validate code quality / perform, and provide users chance for acceptance testing.
In OpenShift these environments are modeled using “projects” (or in Kubernetes terminology “namespaces”).
Jenkins uses the kubernetes configuration files decide how you need to deploy it to the desired environment (Kubernetes cluster) and maybe also need to modify other Kubernetes resources, like configurations, secrets, volumes, policies, and others.
In this case, we set up the following OpenShift projects
- Dev – OpenShift Online project supporting build, unit test, deployment to dev and functional testing
- Test – OpenShfit Online project supporting integration, functional and performance testing
- QA / UAT – OpenShift Online project support user acceptance testing
When running the application in Production, we often need to consider several factors such as scalability, security, privacy. In this case, we decided to setup a dedicated OpenShift (OCP) cluster in a public cloud.
 Source: OpenShift
Source: OpenShift
Conclusion
In conclusion, while microservices architecture offer teams independence, separate CI/CD pipelines and excellent scalability; each new version must be deployed and tested, individually and as part of the entire application or large business capabilities.
Care must be taken when design the CI/CD pipelines to take into considerations the needs of the development, test and operations (essentially DevOps) or you run the risk of missing the value of microservices and Kubernetes.
For additional details, checkout
- Igor Azarny, “CI/CD for Containerized Microservices“, Retrieved July 31, 2019
- Elements of an OpenShift CI/CD Pipeline,
- Redhat OpenShift Container Platform – 3.9 Architecture